The conventional wisdom on code review has a fundamental problem: it treats
speed and quality as a trade-off. Review faster = review worse. Review better =
review slower. This framing produces teams that either rush reviews to hit
velocity targets, or slow reviews to feel thorough — and neither outcome
is what they wanted. The real opportunity is in fixing what reviews are
actually being used for.
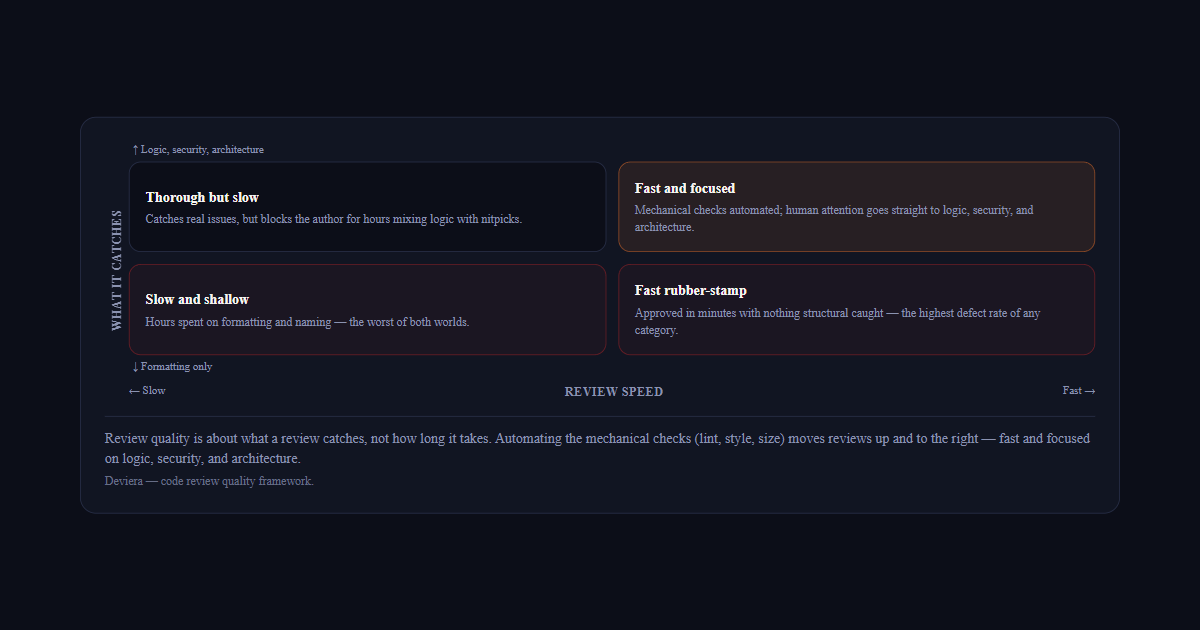
The difference between a fast review and a good review
A fast review and a good review are not opposites. A review that takes 4 hours
and catches two logic bugs is better than a review that takes 6 hours and
catches the same two bugs plus 20 formatting issues. A review that takes
30 minutes and catches nothing structural is worse than both — regardless
of how fast it was.
What it catches
↑ Logic, security, architecture
Thorough but slow
Catches real issues, but blocks the author for hours mixing logic with nitpicks.
Fast and focused
Mechanical checks automated; human attention goes straight to logic, security, and architecture.
Slow and shallow
Hours spent on formatting and naming — the worst of both worlds.
Fast rubber-stamp
Approved in minutes with nothing structural caught — the highest defect rate of any category.
↓ Formatting only
← SlowReview speedFast →
Review quality is about what a review catches, not how long it takes. Automating the mechanical checks (lint, style, size) moves reviews up and to the right — fast and focused on logic, security, and architecture.Deviera — code review quality framework.
The quality of a code review is determined by what it catches, not how long
it takes. Specifically, quality reviews catch:
Logic and algorithmic bugs — incorrect behavior that won't be caught by the existing test suite
Architectural drift — changes that are locally correct but inconsistent with the broader system design
Missing test coverage — new code paths that aren't exercised by the test suite
Low-quality reviews spend most of their time on things that don't require
a second pair of eyes:
Formatting and style (what linters are for)
Naming conventions (what a style guide is for)
Obvious syntax issues (what static analysis is for)
PR description completeness (what a PR template is for)
A Google engineering study found that 90% of bugs caught in code review
could have been caught by the author before submission using static analysis,
linting, and structured self-review checklists. Teams that deploy these pre-review
tools are freeing reviewer time for the work that actually requires a human:
logic, architecture, and security.
PR Cycle Time Benchmark
How fast is your review loop, really?
A quality rubric only helps if reviews actually happen. Benchmark your open-to-merge cycle time against DORA Elite performers — no spreadsheets.
You can identify review quality problems before they result in post-deploy defects.
The leading indicators:
1. Review comments are primarily stylistic.
If >50% of review comments on a PR are about formatting, naming, or
documentation rather than logic and architecture, the reviewer is spending
time on mechanical issues that should be automated. This is measurable
by tagging comment types, or proxied by whether PRs that received extensive
review comments have higher or lower post-deploy defect rates.
2. Single-reviewer approvals on complex PRs.
PRs touching core authentication, payment processing, or data migration
should require two reviewers. Single-reviewer approvals on high-risk code
paths statistically correlate with higher post-deploy defect rates —
not because one reviewer is always insufficient, but because complex PRs
benefit from multiple perspectives.
3. Review turnaround inversely correlates with PR size.
This is a red flag: if large PRs (400+ lines) are getting reviewed faster
than small PRs (under 100 lines), reviewers are rubber-stamping the
complex work and being thorough on the simple work. The correlation
should be the opposite — large PRs should take proportionally longer
to review properly.
4. Low comment-to-approval ratio on high-complexity PRs.
A PR touching core business logic that gets approved with zero comments
is either perfect code (rare) or a rushed review (common). A zero-comment
approval rate above 30% for complex PRs suggests reviews are approvals
rather than reviews.
5. Post-deploy defects introduced in reviewed code.
Track which production defects were introduced in PRs that had completed
code review. If >20% of production bugs were in code that a reviewer
approved without catching the bug, there's a review quality problem —
either reviewer assignment is wrong, PR size is too large, or review
time is insufficient.
How review depth correlates to post-deploy defect rate
The relationship between review quality and production defects is not always
visible in short time windows — which is why most teams don't track it.
A bug introduced in a poorly-reviewed PR may not surface in production for
weeks if it's in an infrequently-used code path.
The teams that have closed this loop consistently find the same pattern:
PRs with multiple reviewers have 30–40% lower post-deploy defect rates than single-reviewer PRs of equivalent complexity
PRs over 500 lines have 2× the post-deploy defect rate of PRs under 200 lines, controlling for code path complexity
PRs reviewed in under 30 minutes have a defect rate 50% higher than PRs reviewed over 2 hours, for equivalent complexity levels
PRs that required zero review comments before approval have the highest defect rate of any category — higher even than PRs with many review comments (which at least signals the reviewer was engaged)
These correlations are not universal laws — they're patterns that suggest where
to audit your review process. If your team's data shows the same patterns,
you have an actionable starting point for improvement.
Building a code review rubric that doesn't slow your team
A review rubric is a structured checklist that helps reviewers focus on
the high-value questions rather than spending review time on mechanical issues.
It doesn't have to be complex:
Before you start reviewing (5 minutes)
Is this PR the right size? If over 400 lines, request decomposition before reviewing
Is there a description that explains the why, not just the what?
Does CI pass? Don't review a PR with failing CI — fix the failures first
During the review (focus on these)
Does the logic match the intended behavior? Are there edge cases not covered?
Are there security implications? (Input validation, auth checks, data exposure)
Does this fit the existing architecture, or does it introduce inconsistencies?
Are the new code paths tested? Is the test coverage sufficient for the risk level?
Skip or automate these
Formatting and style → linter handles this
Naming conventions → style guide + linter handles this
Import ordering, whitespace → linter handles this
PR description completeness → PR template handles this
The rubric's value is not in making reviews longer — it's in making them
more consistent. A reviewer who spends their attention on logic, security,
and architecture will catch more meaningful issues in 2 hours than a reviewer
who spends 3 hours mixing those concerns with formatting comments.
Automating the mechanical parts of review so humans can focus on the hard parts
The goal of pre-review automation is to eliminate the mechanical checklist
items that consume review attention without requiring human judgment:
Linting and formatting — enforce on commit, not in review. A PR that fails lint should never enter the review queue.
Static analysis — catch type errors, null pointer patterns, unused variables before the reviewer sees the PR
Test coverage gates — CI should fail if new code reduces coverage below the team threshold. The reviewer shouldn't need to check test coverage manually.
Automatic reviewer assignment — route PRs to reviewers based on file ownership or prior contribution history. The "who should review this?" question should be answered before the PR is opened, not after it's been sitting for 24 hours.
PR size enforcement — a CI check that warns when a PR exceeds 400 lines removes the awkward conversation about decomposition
When the mechanical work is automated, reviewers arrive at a PR knowing:
it passes linting, it has test coverage, it's the right size, and it's
been routed to the right person. Their attention goes directly to the
questions that require judgment. Reviews get faster because reviewers
aren't wading through noise — and they get better because attention is
focused where it matters.
Speed and quality aren't in tension. Bad review processes are in tension
with both.