
PRs that sit in review aren't just slow — they're actively costing your team.
Every day a PR sits, the cost of merging it increases. Here's why stale PRs
compound into bigger problems, and how to catch them early.
The hidden cost of a stale PR
You open a PR on Monday. By Wednesday, it hasn't been reviewed. By Friday,
there are merge conflicts. By the following Monday, you have 3 hours of
rebasing to do before you can even get feedback.
Here's the math on why this is expensive:
- Day 1: Author context is fresh. Review is easy.
- Day 2: Author starts working on something else. Context decays.
- Day 3: Merge conflicts appear. Rebase needed.
- Day 4+: Author has moved on completely. Review takes 2x longer.
A PR that should take 30 minutes to review on Monday takes 90 minutes on
Thursday because both the author and reviewer have lost context.
What causes PR stagnation
Most stale PRs aren't caused by lazy reviewers. They're caused by structural problems:
- No explicit reviewer assigned: "Anyone can review" means no one does
- Reviewer overload: Too many PRs, not enough reviewers
- Large PRs: Big PRs are harder to review, so they sit longer
- Complex code: PRs in unfamiliar areas take longer to review
- No SLA: "We'll get to it" means "we'll get to it never"
How to measure PR stagnation
Track these metrics:
- PRs open > 48h: Count of PRs that haven't received first review in 48h
- PRs open > 72h: Count of PRs open for 3+ days
- Average time to first review: Time from PR open to first comment
- Abandoned PR rate: PRs closed without merge, as percentage of total
If more than 20% of your PRs are stale (open > 48h), you have a bottleneck.
The escalation pattern
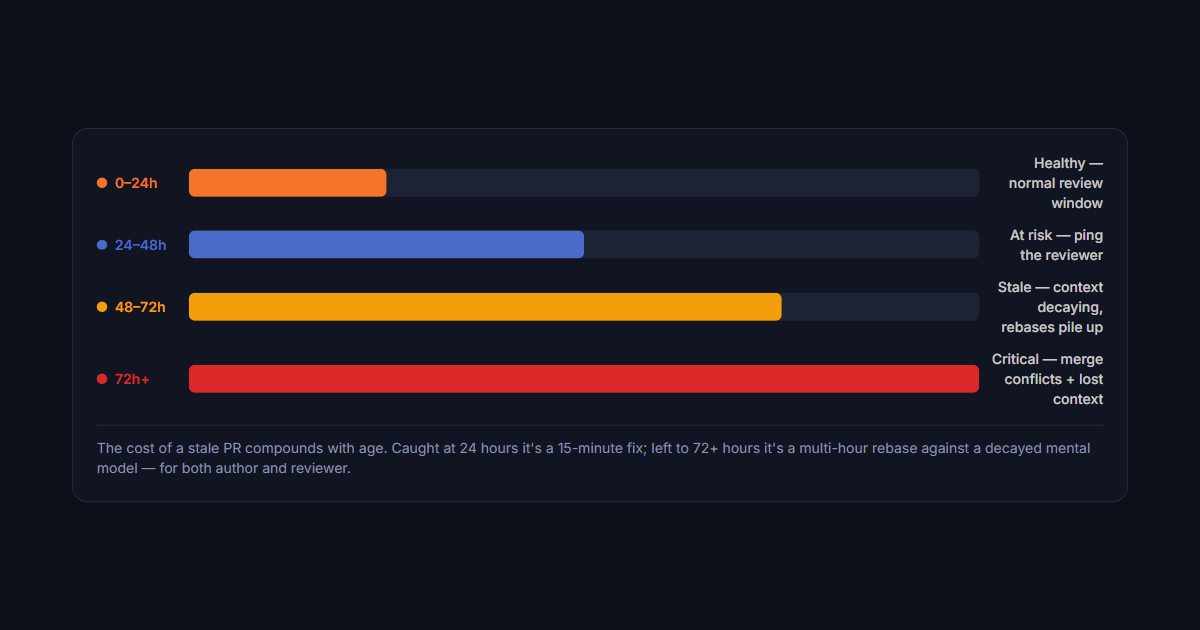
The earlier you catch a stale PR, the cheaper it is to fix. Here's the escalation:
0–24h
Healthy — normal review window
24–48h
At risk — ping the reviewer
48–72h
Stale — context decaying, rebases pile up
72h+
Critical — merge conflicts + lost context
- 0-24h: PR is healthy. Normal review expected.
- 24-48h: PR is at risk. Ping in Slack: "Hey, can someone review this?"
- 48-72h: PR is stale. Escalate: assign specific reviewer, prioritize.
- 72h+: PR is critical. Bring up in team sync. What's blocking?
Prevention strategies
Don't wait for PRs to go stale. Prevent it:
- Assign reviewers at open: Don't leave PRs unassigned
- Enforce PR size limits: Smaller PRs = faster reviews
- Set explicit SLAs: "First review within 4 hours" is a commitment
- Rotate review duty: Make review a shared responsibility
- Auto-remind after 24h: Send automated reminder if no review
What to do this week
- Audit your open PRs: How many are over 48h old?
- Assign explicitly: Every open PR should have a specific reviewer
- Set a team SLA: Agree on "first review within X hours"
- Monitor weekly: Track stale PR count each week, set a target
A stale PR is a warning sign, not a catastrophe. Catch it at 24h, not 72h.
That's the difference between a 15-minute fix and a 3-hour rebase. Deviera's
Signal Feed
detects stale PRs automatically and posts a Slack alert tagging the assigned
reviewers — no manual monitoring needed. See full
PR review time benchmarks
to know what "healthy" looks like at your team size.