
"Our PRs take too long to review" is one of the most common complaints in engineering
teams. But a healthy pull request lifecycle time — from open to first review to merge —
depends on team size, context, and what you're building. Here are realistic benchmarks,
from small teams to enterprise, and what your team's numbers reveal about review health.
Why the benchmark depends on team size
A 5-person team can have a different PR review culture than a 50-person team:
- Small teams (5-15): Everyone knows the codebase. Reviews are fast because there's low context cost.
- Mid-size teams (20-50): Not everyone knows everything. Review takes longer because reviewers need to learn context.
- Large teams (100+): Specialization emerges. Some reviewers become experts in specific domains.
There's no one-size-fits-all number. But there are healthy ranges.
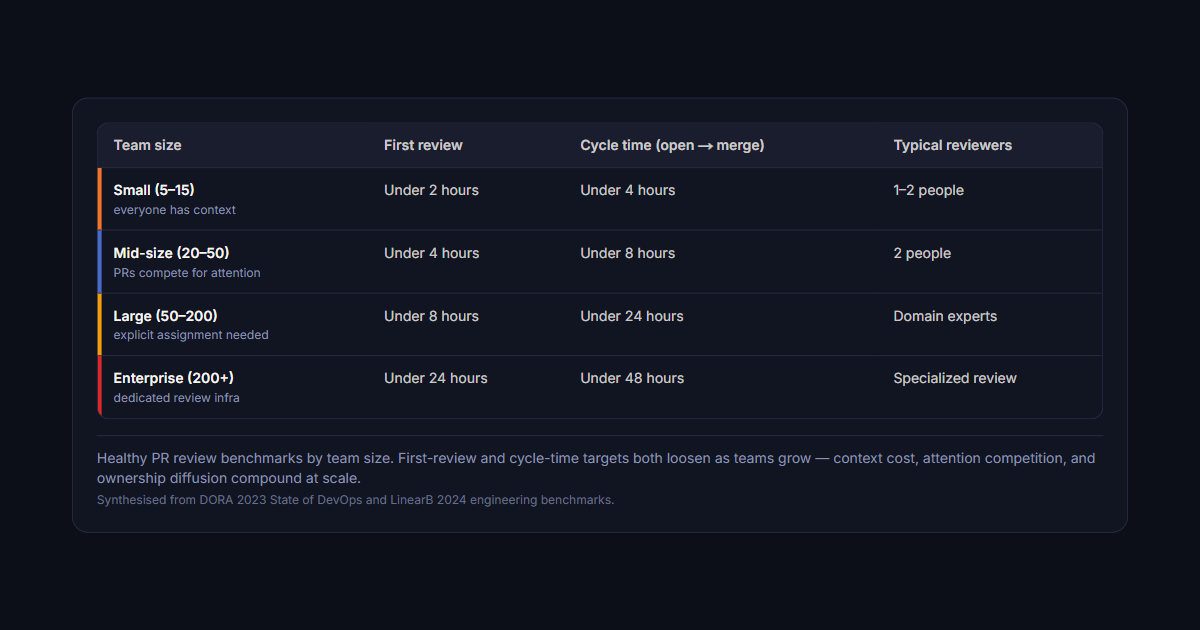
Benchmarks by team size
Small teams (5-15 engineers)
- First review time: Under 2 hours
- Cycle time (open to merge): Under 4 hours
- Review depth: Most PRs reviewed by 1-2 people
Small teams can move fast because everyone has context. If first review time
is over 4 hours, it's usually a capacity problem (not enough reviewers) or
a process problem (no one owns review).
Mid-size teams (20-50 engineers)
- First review time: Under 4 hours
- Cycle time (open to merge): Under 8 hours
- Review depth: Most PRs reviewed by 2 people
At this size, PRs start competing for reviewer attention. Expect first review
time to increase. If it's over 8 hours, there's a bottleneck somewhere.
Large teams (50-200 engineers)
- First review time: Under 8 hours
- Cycle time (open to merge): Under 24 hours
- Review depth: Some PRs need domain experts
Large teams need explicit reviewer assignment. Waiting for "someone" to review
doesn't work when there are 50 people who could do it.
Enterprise (200+ engineers)
- First review time: Under 24 hours
- Cycle time (open to merge): Under 48 hours
- Review depth: Specialized review for different components
At enterprise scale, you need dedicated review infrastructure: reviewer rotation,
domain ownership maps, and explicit SLAs.
| Team size | First review | Cycle time (open → merge) | Typical reviewers |
|---|---|---|---|
| Small (5–15)everyone has context | Under 2 hours | Under 4 hours | 1–2 people |
| Mid-size (20–50)PRs compete for attention | Under 4 hours | Under 8 hours | 2 people |
| Large (50–200)explicit assignment needed | Under 8 hours | Under 24 hours | Domain experts |
| Enterprise (200+)dedicated review infra | Under 24 hours | Under 48 hours | Specialized review |
What your numbers reveal
Here's how to interpret your team's PR review times:
- First review time > 24 hours: Severe bottleneck. Engineers are waiting days for first feedback. Likely need more reviewers or explicit assignment. See the full breakdown of why PRs go stale and how the cost compounds silently.
- Cycle time > 2x first review time: Reviews come back with changes requested, and the author takes a long time to respond. Check for "review churn" — PRs bouncing between author and reviewer without converging.
- Review time variance is high: Some PRs get reviewed in 1 hour, others in 3 days. This suggests inconsistent reviewer availability or uneven code complexity — neither of which self-corrects without measurement.
What affects these numbers
Several factors influence PR review speed:
- PR size: A 200-line PR is faster to review than a 2000-line PR. Enforce PR size limits.
- Code complexity: New features take longer to review than refactors.
- Reviewer availability: Are there enough people who can review this code?
- Time zones: If author and reviewer are in different time zones, expect natural delays.
- Review culture: Some teams expect 24-hour turnaround. Others expect next-day. Set explicit expectations.
How to improve
If your PR review times are unhealthy:
- Measure first: You can't improve what you don't track. Start logging review times.
- Enforce PR size limits: If PRs are too large, they sit longer because no one wants to review them.
- Assign reviewers explicitly: Don't rely on volunteers. Assign specific people.
- Set explicit SLAs: "First review within 4 hours" is a commitment, not a hope.
- Rotate review responsibility: Make review a shared responsibility, not a burden on a few.
- Alert on stale PRs automatically: Rather than checking manually, set up automated alerts when a PR has had no activity for 24–48 hours. Deviera's Signal Feed detects stale PRs and posts a Slack message tagging the assigned reviewers — no manual monitoring required.
The right benchmark is the one that lets your team ship fast without sacrificing
code quality. Find yours, measure it, and improve against it.
Not sure where your team sits? The PR Cycle Time Calculator takes
your first-review time, merge time, and team size and tells you which DORA tier
you're in — plus where your primary bottleneck is. Free, no signup required.
How to track PR review time automatically
Manual tracking — pulling GitHub data into a spreadsheet weekly — degrades quickly.
It's time-consuming, inconsistent, and by the time you see the trend, the bottleneck
has already cost the team two or three sprints. Here's how the main options compare.
GitHub Insights (native)
GitHub's built-in Insights tab shows PR throughput, review turnaround, and code frequency
at the repository level. It's free and requires no setup. The limitation: it's
repository-scoped, not team-scoped. If your team works across multiple repositories,
GitHub Insights gives you fragmented views with no aggregate. It also has no alerting —
you have to check it manually.
LinearB
LinearB connects to GitHub and GitLab and provides per-engineer and per-team PR cycle
time metrics in a dedicated engineering manager dashboard. It calculates first review
time, time to approval, and time to merge separately — useful for pinpointing which
phase of the review process is the bottleneck. LinearB is strong on retrospective
reporting but lighter on real-time alerting when a specific PR goes stale.
Swarmia
Swarmia tracks PR review time as part of its broader developer experience focus. It
surfaces review load imbalances — which engineers are reviewing significantly more than
others — alongside cycle time data. Useful for teams where review burden concentration
is the root cause of slow reviews. Less focused on automated alerting or ticket creation
when thresholds are breached.
Deviera
Deviera tracks PR review time continuously and takes action when a PR crosses your
stale threshold — automatically posting a Slack message, tagging the assigned reviewers,
and creating a ticket if the PR remains unreviewed past a second threshold. The
PR Cycle Time Calculator gives
you an instant benchmark against DORA tiers, and the Signal Feed surfaces stale PRs
in real time alongside CI failures and deployment issues — one view instead of six.
Frequently asked questions
What is a good PR review time?
It depends on team size. For small teams (5–15 engineers), under 2 hours for first
review and under 4 hours to merge is healthy. For mid-size teams (20–50), under 4
hours for first review and under 8 hours to merge. For large teams (50–200), under
8 hours for first review and under 24 hours to merge. These are not arbitrary targets
— they come from DORA research showing that elite-performing teams (top quartile for
deployment frequency and stability) consistently hit these ranges. Teams outside them
show predictably lower deployment frequency.
What is PR cycle time vs. PR review time?
PR cycle time is the total time from when a PR is opened to when it is merged.
PR review time (also called "time to first review") is the time from when the PR
is opened to when a reviewer leaves the first comment or approval. Cycle time
includes review time plus the time the author spends addressing feedback across
all review rounds. Both metrics matter: a short first review time with many
review cycles produces a long cycle time. The best-performing teams minimize both
by keeping PRs small and review feedback specific.
Why do PR review times increase as teams grow?
Three compounding factors: context cost, attention competition, and ownership diffusion.
Context cost rises because reviewers know less of the codebase as it grows, so each
review takes longer to understand. Attention competition increases because more PRs
are open simultaneously, so any individual PR waits longer to get a reviewer's focus.
Ownership diffusion means it's less clear who should review what — without explicit
assignment, PRs sit waiting for a volunteer who never comes. Each factor alone
is manageable; all three together compound exponentially at 30–50 engineers.
How do I reduce PR review time without sacrificing review quality?
The highest-leverage interventions, in order: enforce smaller PRs (under 400 lines
is the standard threshold where review quality drops), assign reviewers explicitly
at PR creation rather than waiting for volunteers, set a written SLA ("first review
within 4 hours during business hours") and make it visible in your team norms, and
automate stale PR alerts so nothing sits unnoticed past your threshold. Review quality
and review speed are not actually in tension — smaller PRs reviewed promptly produce
fewer bugs than large PRs reviewed days later under time pressure.