Featured Article
DORA Metrics
Engineering Strategy
Engineering Metrics
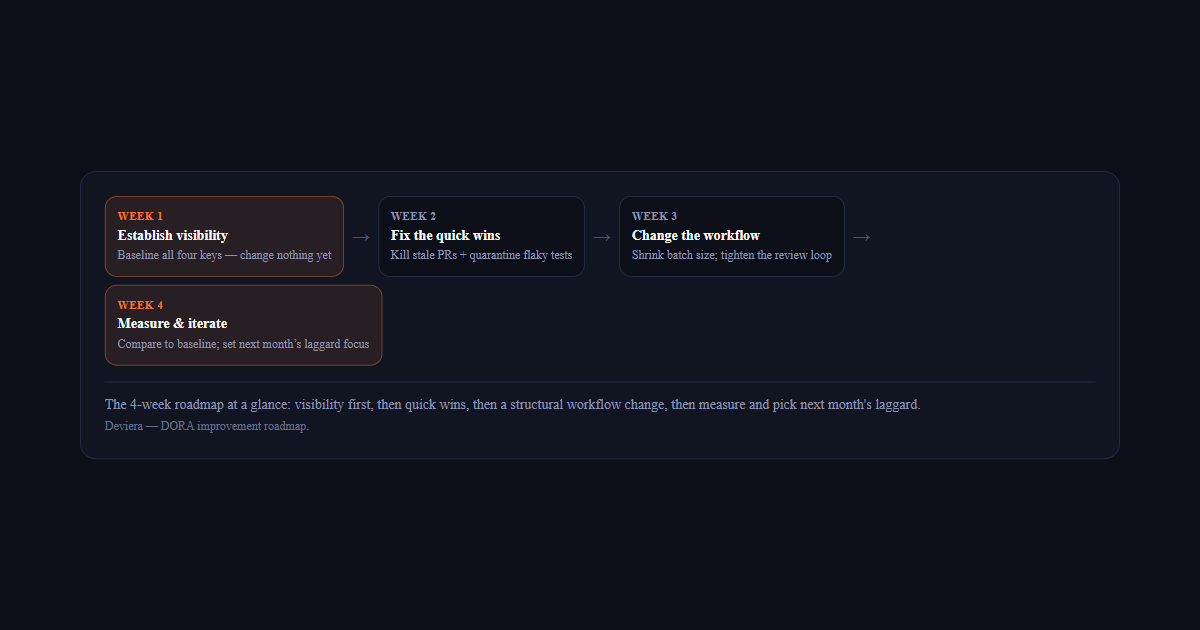
How to Improve Your DORA Metrics: A 4-Week Roadmap
Most teams know their DORA metrics are mediocre but have no plan to fix them. This is a concrete, week-by-week roadmap — from visibility to quick wins to workflow change to measurement — that moves all four keys.
June 2, 2026•12 min read
Read full article