
A change failure rate
above 15% means one in six deployments is breaking production. Elite teams keep CFR below 5%. Here's how to close that gap — and what actually causes CFR to climb in the first place.
What is change failure rate?
Change failure rate (CFR) is one of the four DORA metrics.
It measures the percentage of deployments that require a rollback, hotfix, or patch within a defined window — typically 24–48 hours after deploy.
The formula is simple:
CFR = (failed deployments / total deployments) × 100
A "failed deployment" is any deployment that required remediation: a rollback, an emergency hotfix, a patch pushed within 24 hours. If you deployed 100 times last month and 12 required a rollback or hotfix, your CFR is 12%.
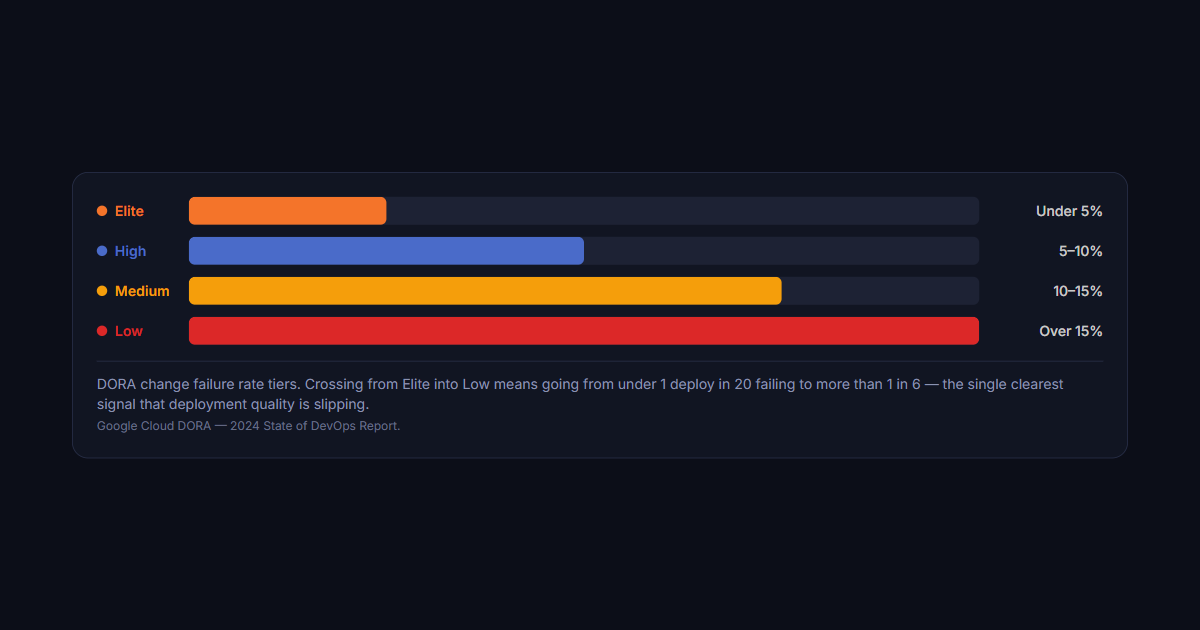
DORA change failure rate benchmarks
Based on the 2024 State of DevOps Report:
- Elite: Less than 5% CFR
- High: 5–10% CFR
- Medium: 10–15% CFR
- Low: More than 15% CFR
Elite
Under 5%
High
5–10%
Medium
10–15%
Low
Over 15%
Most teams landing in the Medium or Low tier are surprised to discover their actual CFR — because they're not measuring it. Incident tracking lives in PagerDuty, deployment data lives in CI/CD logs, and no one has joined the two datasets.
5 practices that reduce change failure rate
1. Reduce deployment batch size
The single most reliable predictor of CFR is deployment size. Large batches (100+ changed files, 20+ commits) have far higher failure rates than small deployments. This isn't because large changes are inherently riskier — it's because large batches are harder to test, harder to review, and harder to roll back when something goes wrong.
The fix: trunk-based development with feature flags. Merge small PRs frequently. Use flags to gate unfinished features from users without delaying deployments. Batch size drops, CFR follows.
2. Invest in automated testing coverage
Teams with Elite CFR rates consistently have higher automated test coverage — especially integration and end-to-end tests covering the critical user paths. Unit tests alone don't prevent production failures; they prevent code-level regressions but miss infrastructure, configuration, and integration issues.
Practical target: 80%+ unit coverage on business logic, with at least one integration test per critical user flow (checkout, auth, data write paths). Use CI gates to block merges when coverage drops.
3. Add deployment health checks and automatic rollbacks
Many CFR failures aren't discovered during deployment — they're discovered 30 minutes later when customers start complaining. Deployment health checks close that window. Configure your deployment pipeline to:
- Run smoke tests immediately post-deploy against the production environment
- Monitor key metrics (error rate, p99 latency, queue depth) for 10 minutes post-deploy
- Trigger automatic rollback if error rate spikes above baseline
Vercel and modern deployment platforms make this straightforward. The key is instrumenting what "healthy" looks like before the deploy, not just checking that the build succeeded.
4. Improve code review quality, not just coverage
CFR often climbs when code review becomes a formality — approvals happen without meaningful review because reviewers are overloaded. Two practices reverse this:
- Limit WIP in review: Cap the number of PRs a single reviewer is responsible for at any given time. Overloaded reviewers approve without reading.
- Require domain ownership review: Changes to authentication, payments, or data migrations should require review from the team member who owns that domain — not just any available reviewer.
5. Track and eliminate flaky tests from CI
Flaky tests kill CFR in a counterintuitive way: teams that tolerate flaky tests start ignoring CI failures. When CI failures are noise, real failures get missed. A 5% flaky test rate means every 20th CI run fails randomly — and engineers learn to "retry and merge." That habit is how real breakage reaches production.
Deviera's CI Intelligence detects flaky tests automatically by analyzing pass/fail patterns across your CI history — flagging tests that alternate results without code changes.
How to measure your current change failure rate
You need two data sources:
- Deployment log: When did each deployment happen? (GitHub Actions, Vercel, CircleCI, or your CD pipeline)
- Failure log: Which deployments were followed by a rollback, hotfix, or incident? (PagerDuty, incident tracker, or a hotfix tag in your Git history)
Join them by deployment timestamp. Deployments where a hotfix or rollback occurred within 24–48 hours = failed deployments. Divide by total deployments for your CFR. An engineering intelligence platform does this join for you continuously, so CFR is tracked rather than reconstructed each quarter.
The fastest way to check where you stand: enter your current numbers into the free
DORA Calculator
and see your tier in seconds.