What is MTTR? Mean Time to Recovery for Engineering Teams
June 2, 2026·7 min read·by Ihab Hamdy
Mean time to recovery (MTTR) is one of the four DORA metrics.
It measures how quickly you restore service after a production failure — the metric that answers "when something breaks, how fast are we back?"
What is MTTR?
MTTR stands for Mean Time To Recovery — the average time it takes to restore service after a failure in production. Together with change failure rate, it forms the stability half of DORA — while deployment frequency and lead time measure throughput.
The clock starts when a failure begins affecting users and stops when normal service is restored. The "mean" is taken across incidents over your measurement window.
DORA Metrics Calculator
See your MTTR tier
MTTR is one of the four DORA keys. Enter yours alongside the other three to see your tier against the 2025 State of DevOps benchmarks in seconds.
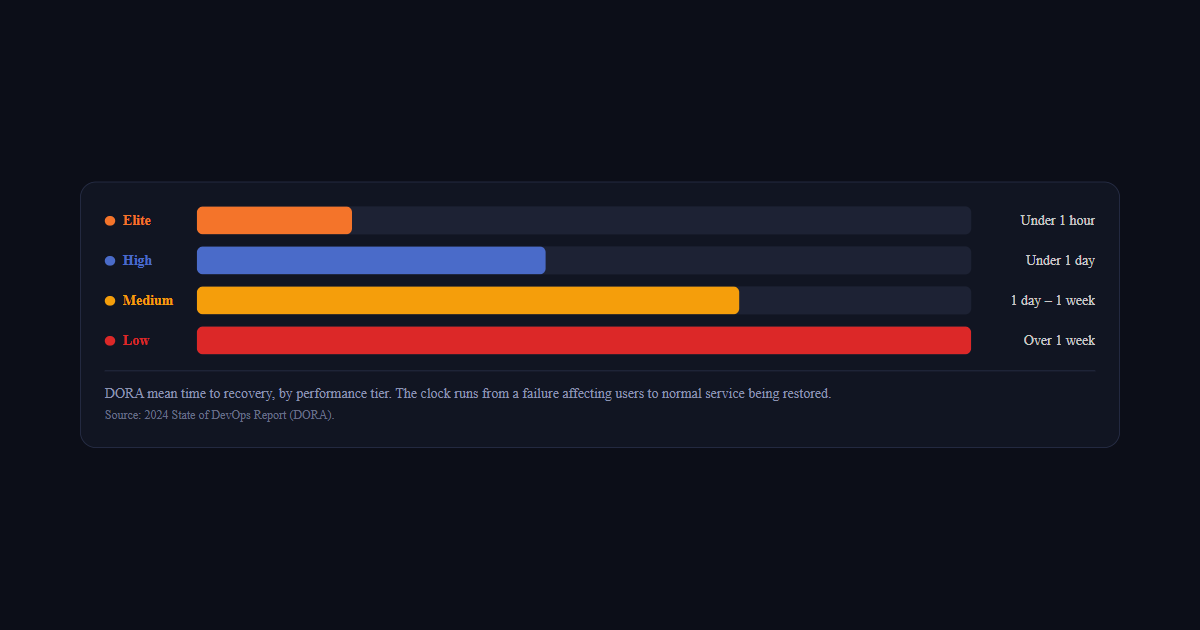
DORA mean time to recovery, by performance tier. The clock runs from a failure affecting users to normal service being restored.Source: 2024 State of DevOps Report (DORA).
Notice that throughput and stability are not in tension. Elite teams deploy more often and recover faster — because small, frequent changes are easier to diagnose and roll back than large, infrequent ones.
A note on the name
"MTTR" is ambiguous in the wider industry — it gets expanded as mean time to recovery, repair, respond, or resolve, which are genuinely different intervals. DORA uses recovery: time to restore service, not time to ship a permanent fix. Pick one definition and hold it constant, or your trend line is meaningless.
The MTTR formula
MTTR is a simple average. Over your measurement window, take the total time
your service spent in a failed state and divide it by the number of incidents:
MTTR = total downtime ÷ number of incidents
If you had four incidents in a month totalling 6 hours of degraded service, your MTTR is 6 ÷ 4 = 1.5 hours. The clock for each incident starts when the failure begins affecting users and stops when normal service is restored — so the quality of your measurement depends entirely on detecting the start accurately. Teams that reconstruct incident start times from memory after the fact almost always understate MTTR.
What shortens MTTR
Fast detection. You can't recover from what you haven't noticed. The largest chunk of MTTR is often the gap between failure and someone realizing it.
Clear ownership. An incident with no obvious owner sits while people figure out whose problem it is.
Easy rollback. If reverting is a one-click operation, recovery is fast. If it's a manual scramble, it isn't.
Context at hand. The commit, the deploy, and the failing check in one place beats hunting across four dashboards.
How automated detection cuts MTTR
The detection gap is where an engineering intelligence platform helps most. When CI fails on main or a deployment fails, Deviera opens a structured incident immediately — tagged to the commit author, with the failing run attached — and posts it to Slack. There's no waiting for someone to notice. When the next build goes green, it auto-resolves the incident and records the recovery time, so MTTR is measured automatically rather than reconstructed after the fact.
MTTR most commonly stands for Mean Time To Recovery — the average time it takes to restore service after a production failure. The acronym is ambiguous across the industry and also gets expanded as mean time to repair, respond, or resolve, which are genuinely different intervals. DORA uses recovery: time to restore service, not time to ship a permanent fix.
How is MTTR calculated?
MTTR is calculated as total downtime divided by the number of incidents over a measurement window: MTTR = total time spent in failure ÷ number of incidents. For each incident the clock starts when the failure begins affecting users and stops when normal service is restored; you then average across all incidents in the period.
What is a good MTTR?
Per the DORA State of DevOps research, elite teams recover in under one hour, high performers in under one day, medium performers in one day to one week, and low performers take more than a week. The largest reducible slice of MTTR is usually detection time — the gap between a failure occurring and someone noticing it.
What does MTTR stand for — repair, respond, or resolve?
All of those expansions are in circulation, which is exactly why the acronym is ambiguous. In the wider industry MTTR is expanded as mean time to recovery, repair, respond, or resolve — and those are genuinely different intervals. DORA uses recovery: the time to restore service, not the time to ship a permanent fix. The practical rule is to pick one definition and hold it constant, otherwise your trend line is meaningless.
What is the difference between MTTA and MTTR?
MTTA (mean time to acknowledge) measures the gap from a failure being detected to someone acknowledging and starting to work on it; MTTR (mean time to recovery, in DORA's usage) measures the full time to restore normal service. MTTA is effectively a slice of the detection-and-response window — and since the largest reducible chunk of MTTR is usually detection time, shortening acknowledgement directly helps MTTR. The key is consistency: decide whether you're measuring acknowledgement, recovery, or a permanent fix, and don't mix them.
What is MTTR in networking or cloud contexts?
The definition doesn't change by domain. In networking, cloud, or any production system, MTTR is total time spent in a failed state divided by the number of incidents (MTTR = total downtime ÷ number of incidents), with the clock starting when the failure begins affecting users and stopping when normal service is restored. What varies between contexts is what counts as 'restored' and how you detect the failure start — the formula and the benchmarks (elite under one hour, and so on) are the same.